
SOAP: A Hybrid Optimizer for Efficient Large Language Model Training
Training large language models (LLMs) is computationally expensive, demanding optimization algorithms that balance speed and generalization performance. This deep dive explores the SOAP optimizer, introduced in "SOAP: Improving and Stabilizing Shampoo using Adam" (Vyas et al., 2024), placing it within the context of recent advances in LLM optimization.
The Optimization Landscape for LLMs: A Balancing Act
Training LLMs involves a crucial trade-off between optimization algorithm speed and the resulting model's ability to generalize well. First-order methods like Adam (Kingma & Ba, 2014) are computationally efficient, but can struggle with optimal generalization and be sensitive to hyperparameter tuning (Alabdullatef, 2024). Recent work suggests that Adam's exponential moving average strategy may hinder convergence to optimal solutions, potentially impacting generalization (Towards AI, 2024).
Second-order methods like Shampoo (Anil et al., 2020) leverage curvature information for potentially superior convergence but come with significantly higher computational costs, especially for large models. This inherent trade-off has driven considerable research into developing optimization algorithms that combine the speed of first-order methods with the potential convergence benefits of second-order methods. Adafactor (Shazeer & Stern, 2018), SGD, and Lion (Liao et al., 2022) are examples of optimizers actively compared in this space (Heek et al., 2024), demonstrating the ongoing search for algorithms suitable for large-scale model training (ScienceDirect, 2024).
Shampoo's Computational Bottleneck
Shampoo's strength lies in its sophisticated preconditioning strategy. However, calculating and inverting the Fisher Information Matrix—a critical step in Shampoo—quickly becomes intractable for large-scale LLMs, leading to substantial computational overhead. Furthermore, the increased complexity in hyperparameter tuning inherent in Shampoo poses a challenge, potentially affecting model performance (Vyas et al., 2024).
SOAP: A Hybrid Approach for Efficient LLM Training
The SOAP optimizer addresses these limitations by combining the computational efficiency of Adam with the theoretically superior convergence of Shampoo. It leverages a crucial mathematical connection between a variant of Shampoo and Adafactor (Shazeer & Stern, 2018). Unlike Shampoo, which recalculates the preconditioning matrix every iteration, SOAP updates it less frequently. Between these preconditioning updates, it performs Adam-style updates within the eigenbasis of Shampoo's preconditioning matrix. This approach exploits the relatively slow evolution of the eigenbasis, allowing Adam updates to contribute effectively while significantly reducing the computational cost of frequent matrix calculations—a more nuanced strategy than merely decreasing the frequency of eigendecompositions.
Key Advantages of SOAP
Reduced Computational Cost: SOAP drastically reduces computational overhead compared to Shampoo by updating the preconditioner less frequently.
Improved Stability: Continual Adam updates throughout the optimization process contribute to the enhanced stability of SOAP, especially beneficial for second-order methods.
Simplified Hyperparameter Tuning: SOAP requires fewer hyperparameters than Shampoo, simplifying the tuning process.
SOAP demonstrably outperforms AdamW and Shampoo in large batch LLM pre-training, achieving a significant reduction in both the number of training iterations and wall-clock time—in certain cases, surpassing a 40% improvement and as much as 35% in reducing the wall-clock time over AdamW and Shampoo (Vyas et al., 2024). This superior performance is evident in Figure 1 below, from the original paper.
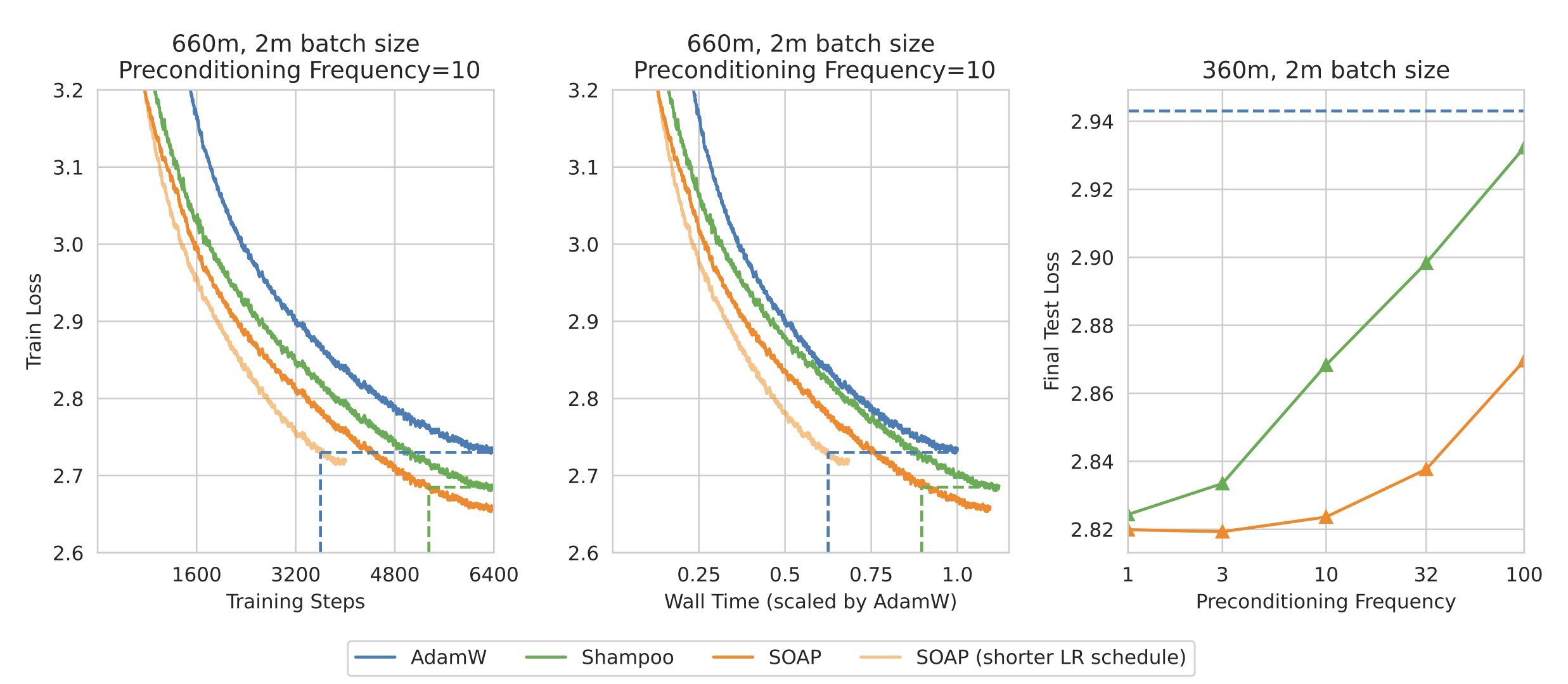
Figure 1: SOAP performance comparison against Adam and Shampoo, highlighting superior iteration and time efficiency. Reducing preconditioning frequency impacts Shampoo more severely than SOAP.
Implementation and Availability
The SOAP optimizer is openly available on GitHub (https://github.com/nikhilvyas/soap). A JAX implementation is also provided (https://github.com/haydn-jones/SOAP_JAX), allowing for customization and accessibility within various deep learning frameworks.
Conclusion
SOAP stands as a promising hybrid optimization algorithm for LLMs. Its ability to leverage the speed and stability advantages of Adam with Shampoo's convergence capabilities positions it as a powerful tool for training increasingly large and complex models. While further benchmarking is crucial to assess SOAP's versatility across diverse models, datasets, and hardware configurations, the initial performance gains are noteworthy. This research exemplifies the critical pursuit of efficient and effective optimization algorithms in the developing field of LLM training.
Unlock More & Get Early Access!
Liked this detailed breakdown? The paid post takes it further with a comprehensive literature review, offering a broader view of the field and putting the paper into a wider context. It’s perfect for those looking to deepen their understanding with a thorough exploration of related research.
